What is a RAG pipeline and How Can It Benefit Your Business?
Building a Retrieval Augmented Generation (RAG) system involves using tools like LangChain. Start by loading different types of information into LangChain, turning it into organized knowledge. Then, input this structured data into a Language Model with Memory (LLM), which keeps track of context for better responses. To make it work well, create specific cues or prompts that guide the model. By continually refining and adjusting this process, you can create a smart and efficient RAG pipeline, bringing all information within easy reach. You can take it a step further by developing chat applications for internal or external use.


RAG, also known as "Retrieval-Augmented Generation," is a powerful tool that can revolutionize the way businesses handle and process information.
Picture RAG as the ultimate blend of Sherlock Holmes and a wizard. When you throw a question, it's as if Holmes skillfully retrieves clues from the archives. But here's where the magic kicks in – RAG doesn't stop at just presenting facts. It's also the wizard that weaves these facts into a coherent and engaging narrative, transforming a mere Q&A session into a captivating dialogue.
In this blog post, we will explore what RAG is, its various forms, its potential applications in different industries, and how you can achieve it for your business.
What is RAG?
RAG is a system that allows users to query information in a natural language format and receive relevant documents and answers in the form of a summary or gist.
It is designed to extract and present the most pertinent information from a vast amount of unstructured data, such as PDFs, text files, and images.
One of the key features of RAG is its ability to understand and process queries in a conversational manner.
How is RAG different from traditional search?
Unlike traditional search engines, RAG goes beyond simple keyword matching and provides meaningful and contextually relevant answers. This makes it an invaluable tool for businesses seeking to extract actionable insights and make informed decisions based on their data.
Retrieval Augmented Generation (RAG) is a paradigm in natural language processing that combines elements of information retrieval and language generation to enhance the quality of generated content.
In RAG models, a retrieval component is employed to fetch relevant information from a pre-existing database or knowledge base.
This retrieved information is then utilized to augment the generation process, influencing the content, coherence, and relevance of the generated text.
By integrating retrieval mechanisms into the generation pipeline, RAG models aim to produce more contextually grounded and information-rich outputs, addressing limitations in conventional language generation models.
This approach is particularly valuable in scenarios where access to external knowledge can contribute to the context-awareness and factual accuracy of generated text.
The different forms of RAG
In business settings, Retrieval Augmented Generation (RAG) takes on various forms, each playing a distinctive role in enhancing efficiency, decision-making, and customer interactions:
1. AI-Enhanced Customer Support:
- RAG is often employed in customer support systems to swiftly retrieve relevant information about products, services, or common queries. It enhances customer interactions by providing instant and accurate responses, ensuring a seamless support experience.
2. Automated Knowledge Base:
- Businesses utilize RAG to create automated knowledge bases that act as intelligent repositories. This allows employees to quickly access information, tutorials, and best practices, streamlining internal processes and fostering a culture of continuous learning.
3. Content Creation Assistance:
- RAG assists in generating content for marketing, documentation, or other business needs. By retrieving and synthesizing information, it aids in crafting coherent and engaging narratives, saving time and effort in content creation processes.
4. Data Analysis and Reporting:
- In data-intensive industries, RAG supports professionals by retrieving relevant insights from vast datasets. It aids in generating reports, summarizing trends, and providing valuable context, empowering decision-makers with actionable information.
5. Meeting Assistance:
- RAG can be integrated into virtual assistants or meeting tools, helping participants by retrieving relevant data or information during discussions. This ensures that meetings are informed and decisions are backed by real-time insights.
6. E-Learning and Training:
- RAG contributes to e-learning platforms by assisting in the retrieval of educational content. It personalizes learning experiences by generating supplementary materials, quizzes, or explanations based on individual needs and progress.
7. Market Research and Competitive Analysis:
- Businesses leverage RAG for market research and competitive analysis. It aids in gathering information about industry trends, competitor strategies, and customer feedback, providing valuable insights for strategic decision-making.
8. Innovation and Idea Generation:
- RAG supports innovation processes by retrieving relevant data, research findings, and creative insights. It acts as a catalyst for idea generation, helping teams stay informed and inspired in their pursuit of novel solutions.
These diverse applications highlight how RAG can be a versatile and valuable asset across various business functions, contributing to productivity, knowledge management, and informed decision-making.
In which industries is RAG most useful?
RAG can be beneficial in a wide range of industries.
For example, in the legal sector, RAG can assist lawyers in quickly finding relevant case precedents, statutes, and legal opinions. In the healthcare industry, RAG can help medical professionals access the latest research papers, clinical guidelines, and treatment protocols. Similarly, in the finance and insurance sectors, RAG can assist with risk assessment, fraud detection, and policy analysis.
How would RAG look like in your business?
Implementing RAG in your business can yield numerous benefits.
Firstly, it can save time and effort by automating the process of finding and extracting relevant information.
Instead of manually sifting through piles of documents, RAG can quickly provide you with the most important details, enabling you to focus on more critical tasks.
Additionally, RAG can enhance collaboration and knowledge sharing within your organization.
By providing a centralized platform for accessing and retrieving information, it ensures that everyone has access to the same up-to-date data.
This can improve productivity, streamline workflows, and foster innovation by enabling employees to make data-driven decisions.
All the pdfs, text, images and IP used by your business exist in different in loose unstructured format in different places.
When you build an RAG pipeline, you devise a way to load that data to a central repository.
Behind the scenes, this data can then be accessed by a Large Learning Model (LLM) with specially engineered prompts. The data can also be stored in a knowledge base.
When anyone in your company queries the data, they can do it using natural language and they will receive the relevant documents and the answer in the form of a gist.
Now, let's discuss how you can achieve RAG for your business.
There are several frameworks and tools available that can help you implement RAG effectively.
Langchain, data loaders and Prompt Engineering
One such framework is LangChain, which provides the necessary infrastructure for building and deploying RAG systems.
It offers data loaders, which can convert unstructured data into a structured knowledge base that RAG can query.
Another essential aspect of implementing RAG is prompt engineering. This involves designing and refining the types of queries that RAG can understand and respond to accurately. By fine-tuning the prompts, you can ensure that RAG provides the most relevant and useful information in response to user queries.
Building a Retrieval Augmented Generation (RAG) system with LangChain
Start by loading different types of information into LangChain, turning it into organized knowledge.
Then, input this structured data into a Language Model with Memory (LLM), which keeps track of context for better responses.
To make it work well, create specific cues or prompts that guide the model.
By continually refining and adjusting this process, you can develop a clever and effective RAG system for data science.
Implementing a RAG pipeline in Python
We show below how you can quickly start building a RAG pipeline in python.
Install langchain and its dependencies using pip in a virtual environment.
Extracting text from data files (text, pdf)
If the data you want to extract is in the form of simple text (for example: computer programs, or email texts), then you can run the following lines of code:
Summary
RAG is a game-changer when it comes to processing and extracting meaningful insights from unstructured data. Its conversational query processing, automation capabilities, and industry-specific applications make it a valuable asset for businesses across various sectors. By implementing RAG with frameworks like LangChain, you can unlock the full potential of your data by making quicker and more informed decisions for your business.
If you would like some help building an AI driven system that solves the entire problem for your business, talk to us.
Click here to schedule an AI strategy call now.

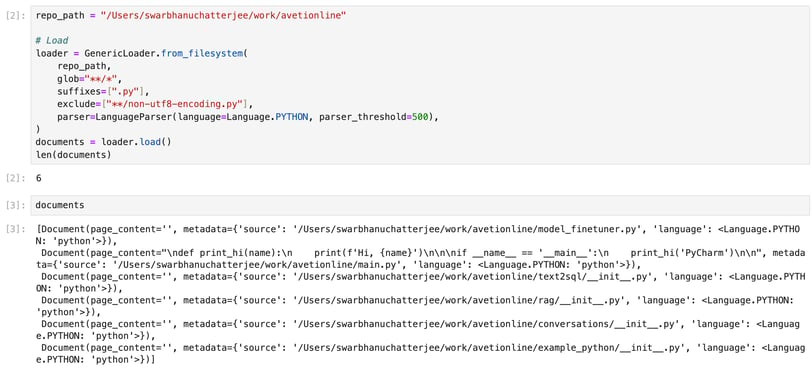
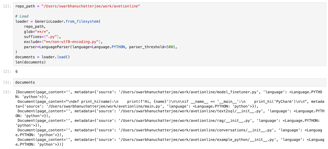
In the above code, we are uploading all files inside a directory and loading the contents into documents. The documents must be then split into text using the code below.
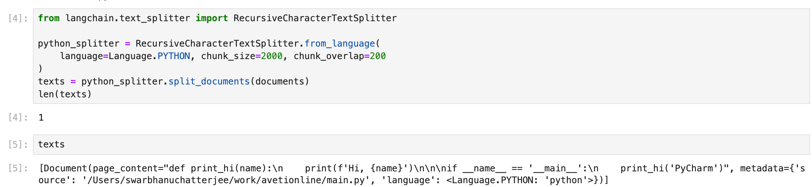
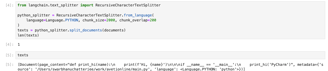
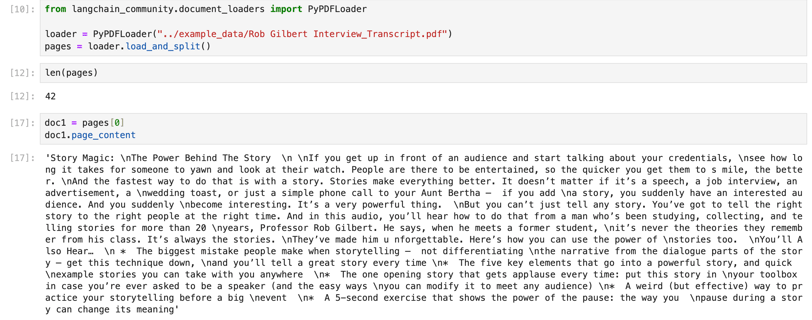
If the data you want to extract is in pdf, you can use the code below to extract well formed pdfs (i.e. pdf that was created using direct methods without too much compression),
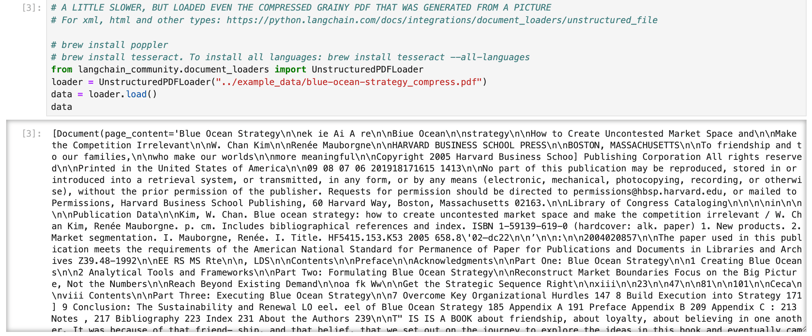
However, sometimes we have pdf documents that have been heavily compressed or which have been converted over from images. For these kinds of pdfs, the method above doesn't work. But you can extract the text from even these kinds of pdfs using the following piece of code:
There are similar loaders in langchain for images, xml and almost all other formats.
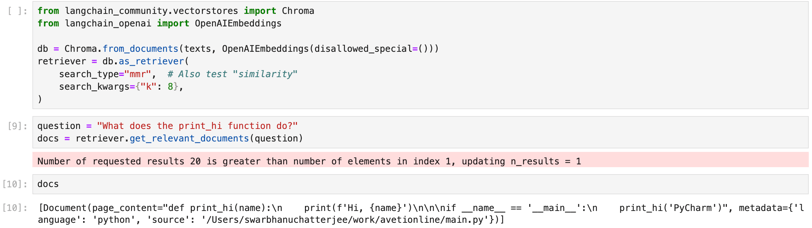
Extracting relevant documents
Extracting relevant documents based on a query made in natural language can be done in 2-3 lines using langchain, as shown below.
Chat using memory
One can easily create a bot in the backend that can continue a chat conversation while remembering the context, as shown below:



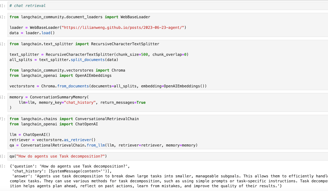
Updating the conversation memory
Data extracted from elsewhere can be fed into the conversation memory as follows,

As one can see, langchain and other frameworks provide a lot of pieces that can be put together to create a RAG pipeline in a few lines of code.
However there are some parts of the RAG pipeline which will still need some customization to make them work without a flaw for your particular business.
Things that need fine tuning
Some areas still require attention:
Building automated pipelines for knowledge bases: When converting text to a knowledge base in the form of a Json or graph structure, complex and long sentences packed with a lot of information often lead to errors. For example, sentences in wikipedia articles on historical topics sometimes don't get rendered well into knowledge graphs.
LLMs don't do a good job when they are given text that fall well outside their domain of knowledge (i.e. the material that they were trained on). Therefore, if you are in healthcare, you would want to work with an LLM trained on troves of medical documents. The same goes for law firms.
Many businesses do not want their data to be exposed to OpenAI. However, the open-source locally saveable models like Llama 2 are not as easy to work with. They may require dedicated hardware and the careful installation of CUDA enabled libraries to train or fine-tune them.